For the past years, my time has been solely dedicated to my product—ScreenshotOne. Almost everything I did for customers only, but today I decided to have fun and write some code without any purpose.
I managed to improve the execution time from 330 seconds to 40 seconds in a few simple steps. The complete solution is available at my GitHub. But if you are curious about the details, keep reading.
About the challenge
The one billion row challenge was created by Gunnar Morling.
The goal of the challenge is to write a program for retrieving temperature measurement values from a text file and calculating the min, mean, and max temperature per weather station. And the file has 1,000,000,000 rows.
The text file has a simple structure with one measurement value per row:
Hamburg;12.0
Bulawayo;8.9
Palembang;38.8
St. John's;15.2
Cracow;12.6
The program should print out the min, mean, and max values per station, alphabetically ordered like so:
{Abha=5.0/18.0/27.4, Abidjan=15.7/26.0/34.1, Abéché=12.1/29.4/35.6, Accra=14.7/26.4/33.1, Addis Ababa=2.1/16.0/24.3, Adelaide=4.1/17.3/29.7, ...}
The goal of the challenge is to create the fastest implementation for this task. It was initially supposed to be only for Java programs, but people started to implement it in C++, Rust, and even SQL.
But I decided to go with Go.
My setup
Running the same program on different hardware and different will have a different result. But it is not relevant in this post, because I won’t change my setup over it. Just in case, I use:
- MacBook Pro 2021 with the Apple M1 Max chip;
- 32 GB memory;
- macOS Sonoma 14.2.1.
Only the percentage of the improvement matters, not the absolute numbers.
1. The first naive implementation
Before optimizing and making the fastest working version, I decided that I first need to make at least a naive implementation of the challenge and to check that I understand how it works.
I just wrote the simple code that does the job:
package main
import (
"bufio"
"fmt"
"log"
"math"
"os"
"sort"
"strconv"
"strings"
)
type StationAverage struct {
sum float64
count int
min float64
max float64
}
func main() {
file, err := os.Open("./measurements.txt")
if err != nil {
log.Fatal(err)
}
defer file.Close()
measurements := make(map[string]*StationAverage)
stations := make([]string, 0)
scanner := bufio.NewScanner(file)
for scanner.Scan() {
row := scanner.Text()
parts := strings.Split(row, ";")
station := parts[0]
temperature, err := strconv.ParseFloat(parts[1], 64)
if err != nil {
log.Fatal(err)
}
_, exists := measurements[station]
if exists {
measurements[station].max = math.Max(measurements[station].max, temperature)
measurements[station].min = math.Min(measurements[station].min, temperature)
measurements[station].sum += temperature
measurements[station].count += 1
} else {
measurements[station] = &StationAverage{
max: temperature,
min: temperature,
sum: temperature,
count: 1,
}
stations = append(stations, station)
}
}
if err := scanner.Err(); err != nil {
log.Fatal(err)
}
sort.Strings(stations)
fmt.Print("{")
for i, station := range stations {
average := measurements[station]
fmt.Printf("%s=%.1f/%.1f/%.1f", station, average.min, average.sum/float64(average.count), average.max)
if i != (len(stations) - 1) {
fmt.Print(", ")
}
}
fmt.Print("}")
}
The algorithm is simple:
- I just iterate over every line, and compute the max, min, sum, and the number of the measurements per station.
- Then I sort station names.
- And print results.
As you might guess, it takes a ton of time to process. Yes, the resulting time is almost 6 minutes:
$ time go run main.go > result.txt
go run main.go > result.txt 331.85s user 11.04s system 96% cpu 5:54.32 total
If I were to profile the program, we would see that most of the time is consumed by syscall, basically reading from the file:
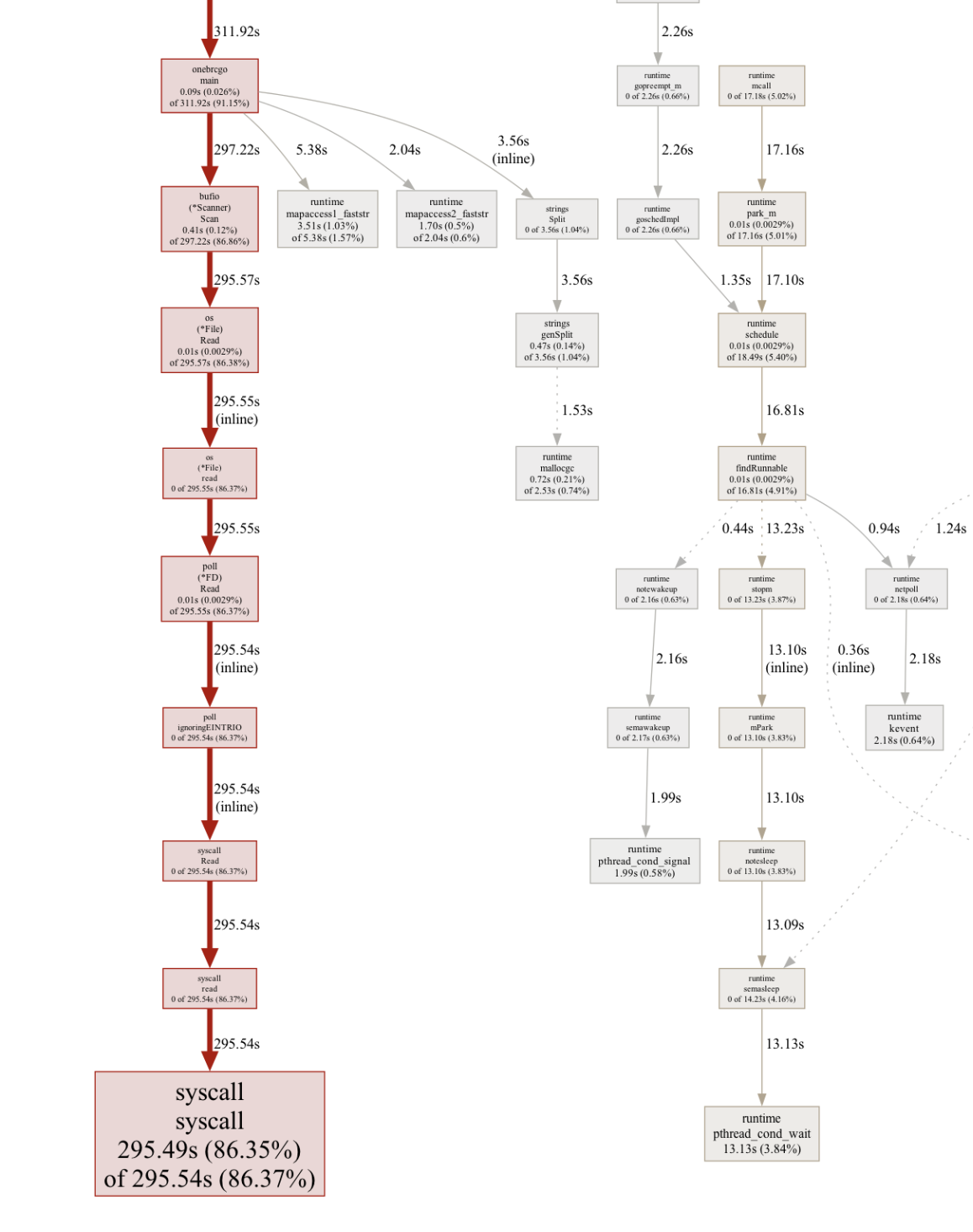
What is possible?
That surprised me a lot, but just reading the file without any computations takes around 20 seconds. That’s the maximum time I can achieve if parallelizing reading the file and processing it doesn’t make it faster.
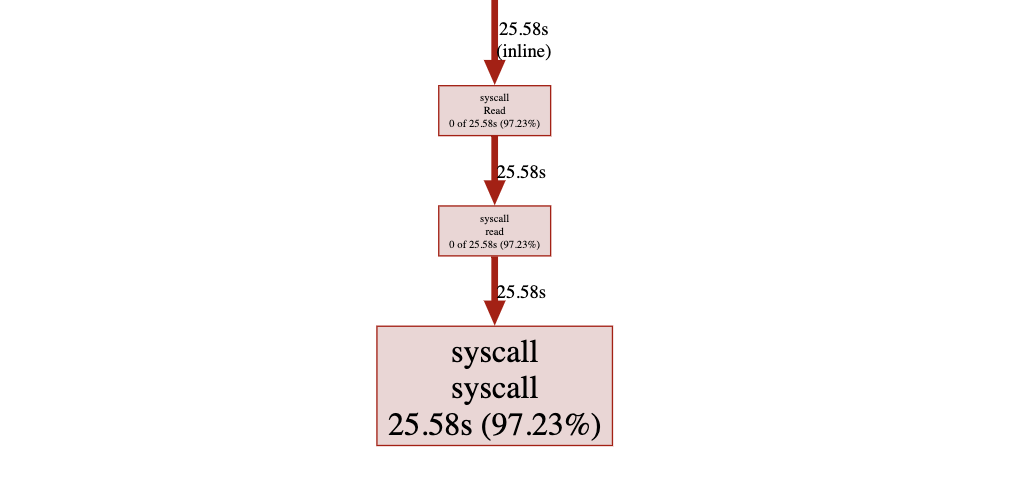
One of the reasons why just reading the file without any computations works faster than reading files and computing things might be due to how OS uses buffering and optimization for reading files. Having intermittent computations between file reads makes reading fragmented and OS probably can optimize well enough.
What if we could capitalize on that idea?
2. Simple concurrency to the rescue
I am splitting reading the file and computations into two separate routines that will communicate via a buffer channel. Will it improve the performance or not? What is your best guess?
func main() {
file, err := os.Open("./measurements.txt")
if err != nil {
log.Fatal(err)
}
defer file.Close()
var wg sync.WaitGroup
lines := make(chan string, 100000)
scanner := bufio.NewScanner(file)
wg.Add(1)
go func() {
defer wg.Done()
for scanner.Scan() {
lines <- scanner.Text()
}
close(lines)
if err := scanner.Err(); err != nil {
log.Fatal(err)
}
}()
measurements := make(map[string]*StationAverage)
stations := make([]string, 0)
wg.Add(1)
go func() {
defer wg.Done()
for line := range lines {
parts := strings.Split(line, ";")
station := parts[0]
temperature, err := strconv.ParseFloat(parts[1], 64)
if err != nil {
log.Fatal(err)
}
_, exists := measurements[station]
if exists {
measurements[station].max = math.Max(measurements[station].max, temperature)
measurements[station].min = math.Min(measurements[station].min, temperature)
measurements[station].sum += temperature
measurements[station].count += 1
} else {
measurements[station] = &StationAverage{
max: temperature,
min: temperature,
sum: temperature,
count: 1,
}
stations = append(stations, station)
}
}
sort.Strings(stations)
}()
wg.Wait()
fmt.Print("{")
for i, station := range stations {
average := measurements[station]
fmt.Printf("%s=%.1f/%.1f/%.1f", station, average.min, average.sum/float64(average.count), average.max)
if i != (len(stations) - 1) {
fmt.Print(", ")
}
}
fmt.Print("}")
}
The answer is not.
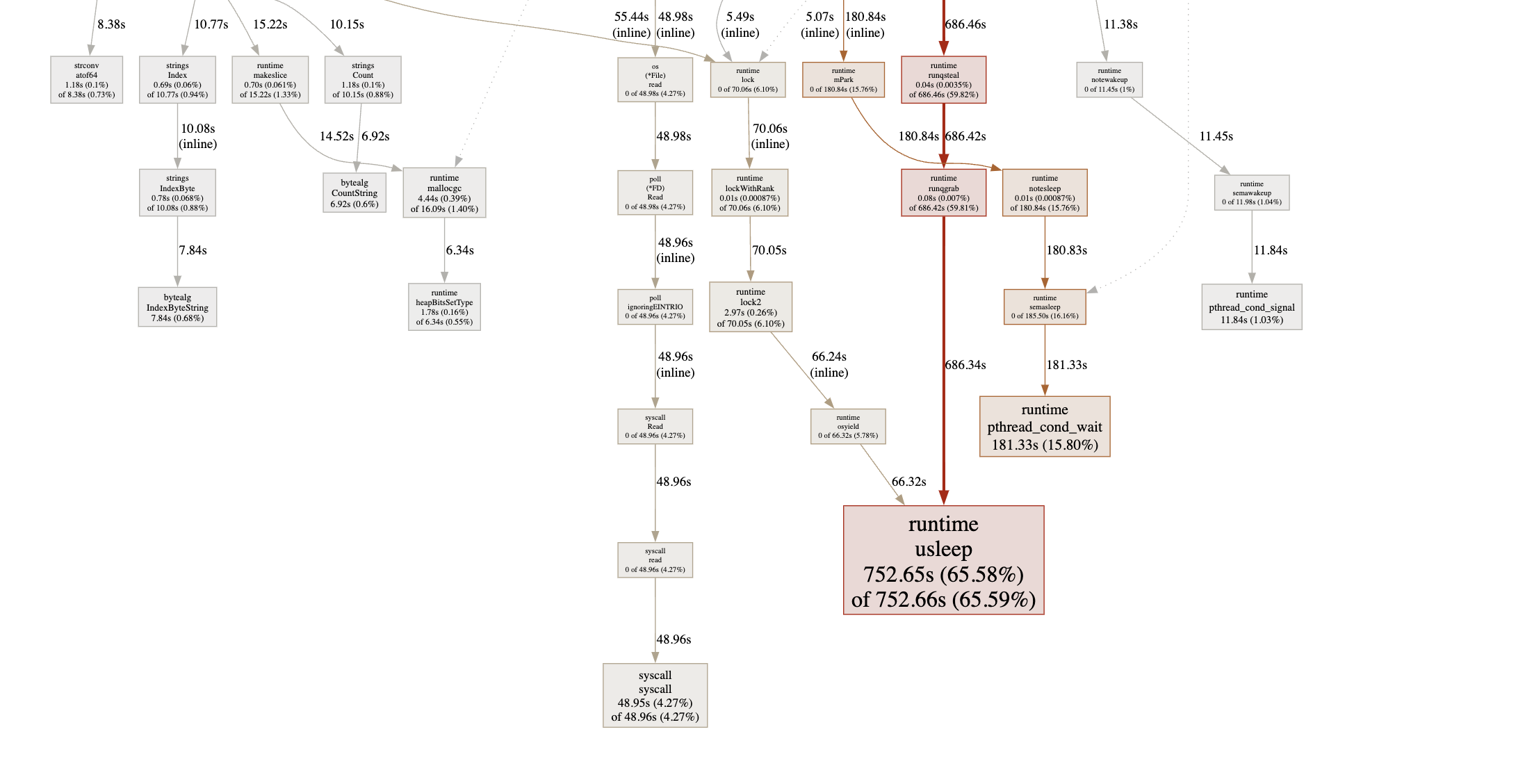
Yes, syscall now takes much less time, but computations and synchronization take more time and we got the same results—around 5 minutes!
But why? It seems from the profile that computations take much more time than reading the file which essentially means that reading the file will be blocked and will be slowed down.
First of all, I underestimated how I incorrectly was using the map access, look at this code:
_, exists := measurements[station]
if exists {
measurements[station].max = math.Max(measurements[station].max, temperature)
measurements[station].min = math.Min(measurements[station].min, temperature)
measurements[station].sum += temperature
measurements[station].count += 1
} else {
measurements[station] = &StationAverage{
max: temperature,
min: temperature,
sum: temperature,
count: 1,
}
stations = append(stations, station)
}
It doesn’t matter for simple programs, but when processing one billion entries, it is a real bottleneck.
Let’s rewrite the program and see if my hypothesis was right and if we can improve the running time:
package main
import (
"bufio"
"fmt"
"log"
"math"
"os"
"sort"
"strconv"
"strings"
"sync"
)
type StationMetrics struct {
sum float64
count int
min float64
max float64
}
func compute(lines chan string) (map[string]*StationMetrics, []string) {
measurements := make(map[string]*StationMetrics)
stations := make([]string, 0)
for line := range lines {
parts := strings.Split(line, ";")
station := parts[0]
temperature, err := strconv.ParseFloat(parts[1], 64)
if err != nil {
log.Fatal(err)
}
s, exists := measurements[station]
if exists {
s.max = math.Max(s.max, temperature)
s.min = math.Min(s.min, temperature)
s.sum += temperature
s.count += 1
} else {
measurements[station] = &StationMetrics{
max: temperature,
min: temperature,
sum: temperature,
count: 1,
}
stations = append(stations, station)
}
}
sort.Strings(stations)
return measurements, stations
}
func readFile(scanner *bufio.Scanner, lines chan string) {
for scanner.Scan() {
lines <- scanner.Text()
}
}
func main() {
file, err := os.Open("./measurements.txt")
if err != nil {
log.Fatal(err)
}
defer file.Close()
var wg sync.WaitGroup
lines := make(chan string, 100000)
scanner := bufio.NewScanner(file)
wg.Add(1)
go func() {
defer wg.Done()
readFile(scanner, lines)
close(lines)
if err := scanner.Err(); err != nil {
log.Fatal(err)
}
}()
var measurements map[string]*StationMetrics
var stations []string
wg.Add(1)
go func() {
measurements, stations = compute(lines)
defer wg.Done()
}()
wg.Wait()
fmt.Print("{")
for i, station := range stations {
average := measurements[station]
fmt.Printf("%s=%.1f/%.1f/%.1f", station, average.min, average.sum/float64(average.count), average.max)
if i != (len(stations) - 1) {
fmt.Print(", ")
}
}
fmt.Print("}")
}
Now, let’s profile it:
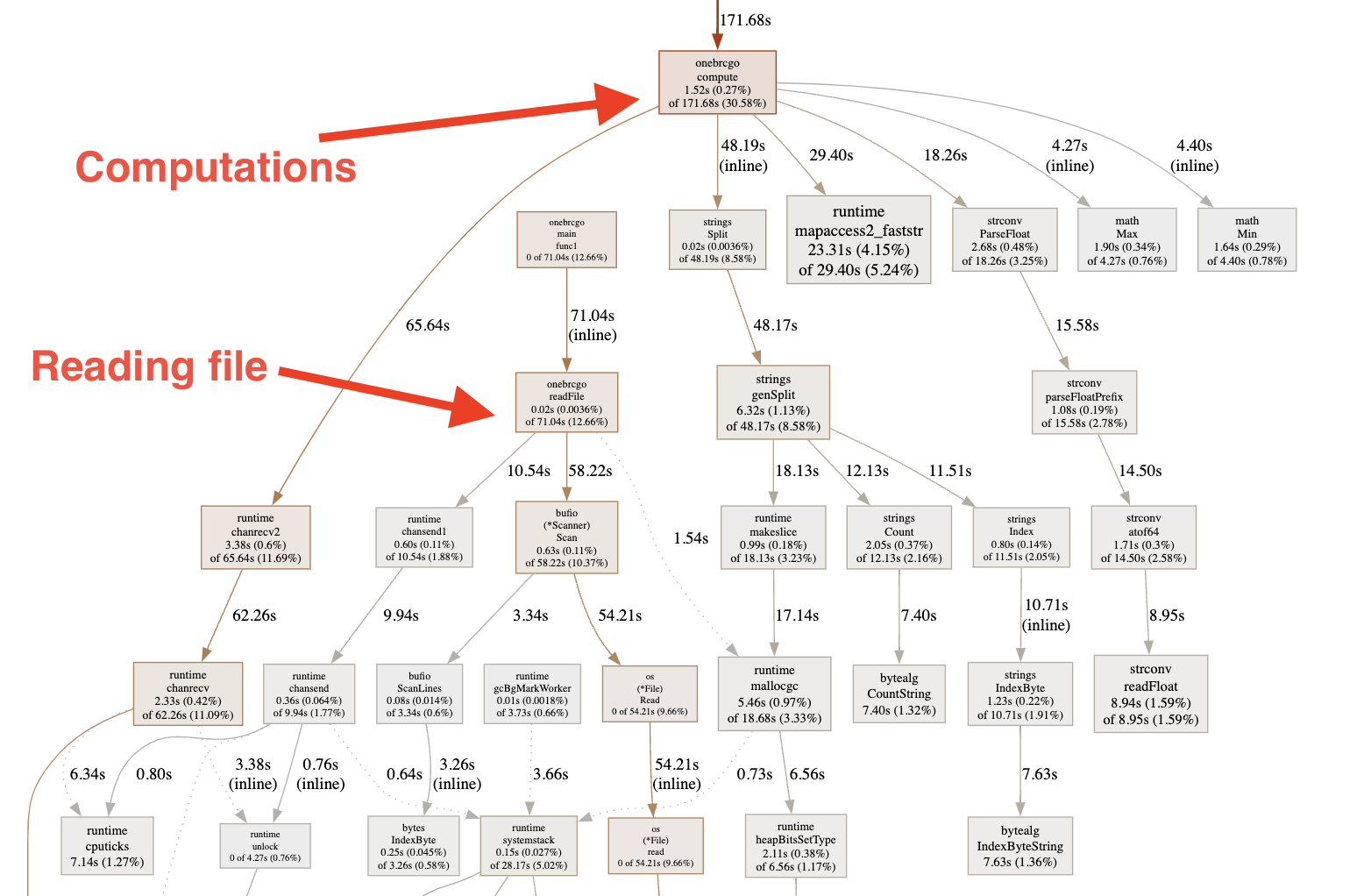
And indeed the execution time has been improved to 243 seconds. It is around 30% improvement!
What’s next? I see a few approaches to try:
- To profile further and reduce the computation time.
- Read the file in parallel with many readers and spawn more workers for computations, too.
3. Faster computations
I will go iteratively and improve computations step by step by profiling and optimizing the slowest code parts.
Avoiding using strings.Split() and rewriting that to a custom simple function allowed improving time up to 160 seconds:
func parse(row string) (string, float64, error) {
for p, r := range row {
if r == ';' {
station, data := row[:p], row[p+len(";"):]
temperature, err := strconv.ParseFloat(data, 64)
if err != nil {
return "", 0, fmt.Errorf("failed to parse the temperature \"%s\" as a number", data)
}
return station, temperature, nil
}
}
return "", 0, fmt.Errorf("failed to locate \";\" in \"%s\"", row)
}
func compute(lines chan string) (map[string]*StationMetrics, []string) {
measurements := make(map[string]*StationMetrics)
stations := make([]string, 0)
for line := range lines {
station, temperature, err := parse(line)
if err != nil {
log.Fatal(err)
}
s, exists := measurements[station]
if exists {
s.max = math.Max(s.max, temperature)
s.min = math.Min(s.min, temperature)
s.sum += temperature
s.count += 1
} else {
measurements[station] = &StationMetrics{
max: temperature,
min: temperature,
sum: temperature,
count: 1,
}
stations = append(stations, station)
}
}
sort.Strings(stations)
return measurements, stations
}
Now, most of the time on computations is spent on working with channels which means that computations work faster than reading the file:
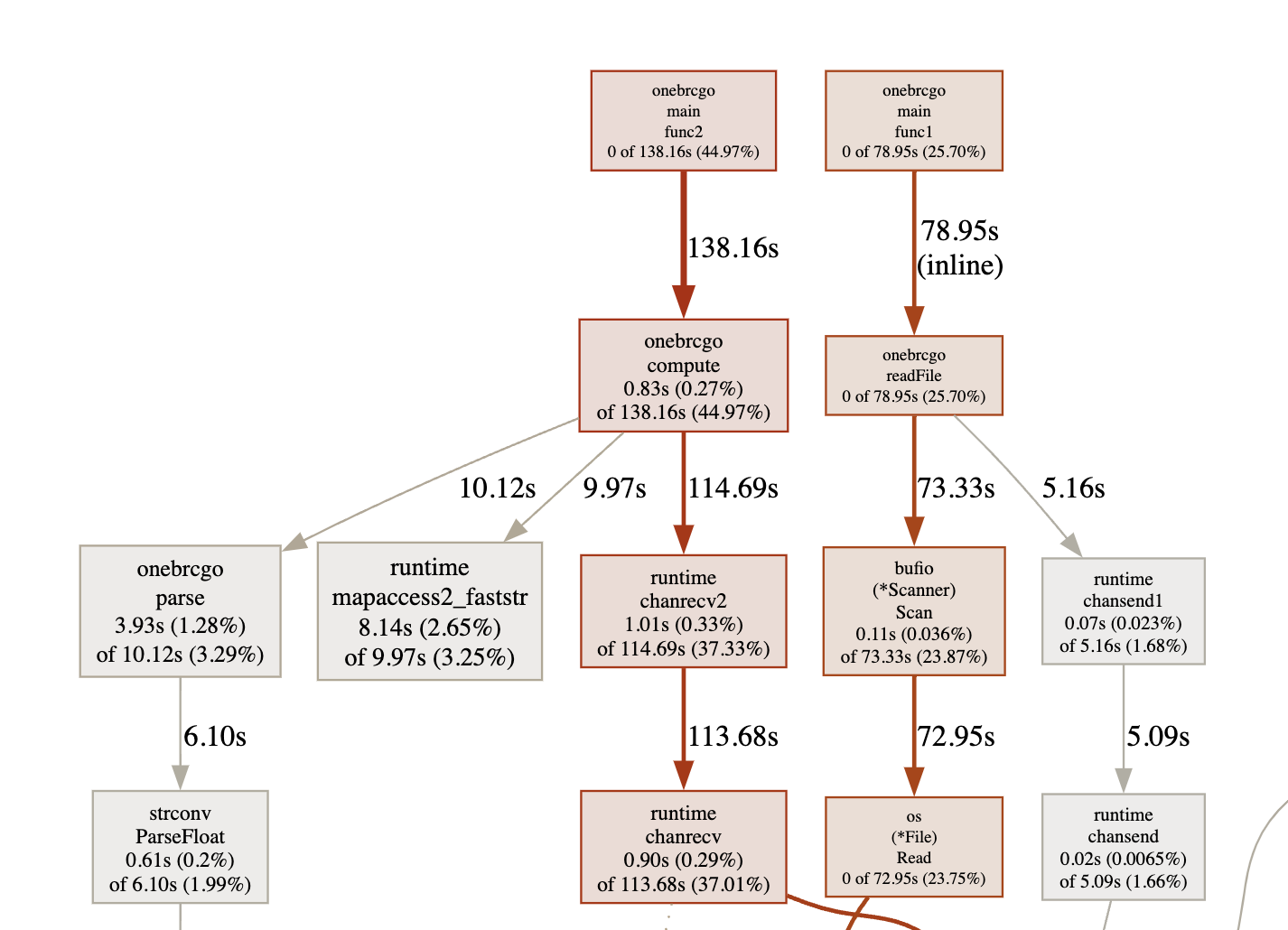
4. Complex concurrency
Since now the problem is not in computations, but in reading the file, let’s try to read the file in parallel and to perform computations in parallel, too.
The idea is simple:
- Read the file size.
- Split the file into chunks of equal size by positions.
- Start reading the file in parallel without any interference between the reading functions.
- Launch the
computefunction and receive data from not one but many channels to avoid contentions.
Let’s try:
package main
import (
"bufio"
"errors"
"fmt"
"io"
"log"
"math"
"os"
"sort"
"strconv"
"sync"
)
type StationMetrics struct {
sum float64
count int
min float64
max float64
}
func parse(row string) (string, float64, error) {
for p, r := range row {
if r == ';' {
station, data := row[:p], row[p+len(";"):]
temperature, err := strconv.ParseFloat(data, 64)
if err != nil {
return "", 0, fmt.Errorf("failed to parse the temperature \"%s\" as a number", data)
}
return station, temperature, nil
}
}
return "", 0, fmt.Errorf("failed to locate \";\" in \"%s\"", row)
}
func compute(lines chan string) map[string]*StationMetrics {
measurements := make(map[string]*StationMetrics)
for line := range lines {
station, temperature, err := parse(line)
if err != nil {
log.Fatal(err)
}
s, exists := measurements[station]
if exists {
s.max = math.Max(s.max, temperature)
s.min = math.Min(s.min, temperature)
s.sum += temperature
s.count += 1
} else {
measurements[station] = &StationMetrics{
max: temperature,
min: temperature,
sum: temperature,
count: 1,
}
}
}
return measurements
}
func findNextNewLinePosition(file *os.File, startPosition int64) (int64, error) {
_, err := file.Seek(startPosition, io.SeekStart)
if err != nil {
return 0, fmt.Errorf("failed to set the offset to %d: %w", startPosition, err)
}
var buf [1]byte
for {
n, err := file.Read(buf[:])
if err != nil {
if err == io.EOF {
return 0, io.EOF
}
return 0, err
}
startPosition += int64(n)
if buf[0] == '\n' {
return startPosition, nil
}
}
}
func readFile(scanner *bufio.Scanner, lines chan string) {
for scanner.Scan() {
lines <- scanner.Text()
}
}
func createScanners(filePath string, chunkNumber int) ([]*bufio.Scanner, func() error, error) {
fileInfo, err := os.Stat(filePath)
if err != nil {
return nil, nil, fmt.Errorf("failed to get the file information: %w", err)
}
files := make([]*os.File, chunkNumber)
closeFiles := func() error {
errs := make([]error, 0)
for _, file := range files {
if file == nil {
continue
}
err := file.Close()
if err != nil {
errs = append(errs, err)
}
}
if len(errs) > 0 {
return fmt.Errorf("failed to close files: %w", errors.Join(errs...))
}
return nil
}
fileSize := fileInfo.Size()
chunkSize := fileSize / int64(chunkNumber)
var startPosition int64
scanners := make([]*bufio.Scanner, chunkNumber)
for i := 0; i < chunkNumber; i++ {
fileName := filePath
file, err := os.Open(fileName)
if err != nil {
closeFiles()
return nil, nil, fmt.Errorf("failed to open file %s: %w", filePath, err)
}
nextPosition, err := findNextNewLinePosition(file, startPosition+chunkSize)
if i == chunkNumber-1 && err == io.EOF {
nextPosition = fileSize
} else if err != nil {
closeFiles()
return nil, nil, fmt.Errorf("failed to find the closest new line for position %d: %w", startPosition, err)
}
files[i] = file
scanners[i] = bufio.NewScanner(io.NewSectionReader(file, startPosition, nextPosition-startPosition))
startPosition = nextPosition
}
return scanners, closeFiles, nil
}
func main() {
// filePath := os.Args[1:][0]
filePath := "./measurements.txt"
chunks := 10
bufferSize := 1000000
scanners, closeFiles, err := createScanners(filePath, chunks)
if err != nil {
log.Fatal(err)
}
defer closeFiles()
channels := make([]chan string, chunks)
for i := 0; i < chunks; i++ {
channels[i] = make(chan string, bufferSize)
}
var wg sync.WaitGroup
for i, scanner := range scanners {
wg.Add(1)
go func(scanner *bufio.Scanner, i int) {
defer wg.Done()
readFile(scanner, channels[i])
close(channels[i])
if err := scanner.Err(); err != nil {
log.Fatal(err)
}
}(scanner, i)
}
allMeasurements := make(map[string]*StationMetrics, 0)
lock := sync.Mutex{}
for i := 0; i < chunks; i++ {
wg.Add(1)
go func(i int) {
defer wg.Done()
measurements := compute(channels[i])
lock.Lock()
defer lock.Unlock()
for station, metrics := range measurements {
totalMetrics, exists := allMeasurements[station]
if exists {
totalMetrics.max = math.Max(metrics.max, totalMetrics.max)
totalMetrics.min = math.Min(metrics.min, totalMetrics.min)
totalMetrics.sum += metrics.sum
totalMetrics.count += metrics.count
} else {
allMeasurements[station] = metrics
}
}
}(i)
}
wg.Wait()
allStations := make([]string, 0)
for station := range allMeasurements {
allStations = append(allStations, station)
}
sort.Strings(allStations)
fmt.Print("{")
for i, station := range allStations {
average := allMeasurements[station]
fmt.Printf("%s=%.1f/%.1f/%.1f", station, average.min, average.sum/float64(average.count), average.max)
if i != (len(allStations) - 1) {
fmt.Print(", ")
}
}
fmt.Print("}")
}
And the results are impressive. We are down to almost 40 seconds. It is around 600% improvement!
4. What’s next?
There are still a lot of opportunities:
- Tune the channel buffer size and see what works best.
- Tune the number of routines to find the optimal execution time.
- Improve reading the file by mapping it to the memory (if available in Go).
- Try to launch more file readers or more compute functions in parallel.
And many more.
Summary
By the way, I tried to chat with ChatGPT and the program it wrote was not bad, I think it might have given good results, close to what I wrote.
But the program just didn’t work on the first run and it required a lot of tuning.
Long story short, it was a joyful day and I reminded myself again how good is Go at managing concurrency. But at the cost of complexity.